Claude Code's Source Code Leak: The Harness Is a Blueprint for Steering Agent Systems

In this article:
- The accident: a missing line in .npmignore
A 59.8 MB source map shipped to npm. For the second time. 1,900 files of unobfuscated TypeScript became public in hours. - The agent loop: from one prompt to a chain reaction
The while-loop is trivial. The engineering is in how the model fans out from one prompt into a coherent sequence of tool calls. - The tools: every capability is a typed contract
29,000 lines of tool definitions. The general-purpose tool actively discourages its own use. - The scars: security shaped by 23 real attacks
Each numbered check maps to an exploitation attempt someone actually tried. Auto mode runs a separate classifier per action. - The compression: context management as infrastructure
Three tiers. A missing circuit breaker burned 250,000 API calls per day. Cache-break vectors tracked like production incidents. - The memory: an index that distrusts itself
Not a knowledge store. A lightweight index where every recalled fact is treated as a stale claim. - Sub-agents: fork, teammate, worktree
Three ways to spawn workers. Fork inherits the parent's KV cache and skips re-processing shared context. - The routing: not every decision needs Opus
Regex for frustration. Haiku for permissions. Sonnet for safety. Opus only where it matters. - The reference: Claude Code vs OpenCode
The leading open-source alternative uses the same loop. The differences are in the harness. - Not all agent systems are the same
Coding, customer support, sales, and vertical workflow agents all have different trust models, tool sets, and compliance needs. Which Claude Code patterns transfer depends on which type you are building. - What this changes
Eight patterns. One conclusion: the scaffolding is the product.
It is 11pm in Singapore. March 31, 2026. A developer runs npm pack on @anthropic-ai/claude-code@2.1.88 and notices the package is 59.8 MB.
That is not normal. A CLI tool should not weigh 60 megabytes. The extra weight is a file called cli.js.map. A source map. The complete, unobfuscated TypeScript source of Anthropic's flagship coding agent.
A missing *.map entry in .npmignore, combined with Bun generating source maps by default. 1,900 files. 512,000+ lines. Every tool definition, every permission check, every prompt assembly function, every memory consolidation routine. Public.
This was the second time it happened. The first was on launch day, February 24, 2025. The same gap in the same build process, unfixed for thirteen months.
The community found hidden features, unreleased capabilities, and internal flags that made for good headlines. But the more interesting story was quieter: 512,000 lines of production agent architecture, written by the team running one of the most used AI coding tools in the world.
The core finding, buried in the noise: the model is not the agent. The harness is.
The same Claude Opus scored 42% with a generic scaffold and 78% with Claude Code's harness on CORE-Bench, a scientific paper reproducibility benchmark from Princeton. Same model, same weights, nearly double the score.
And that understates it. Both configurations had tool use. The 42% baseline was a simple harness, not a raw model. A model with no tool-use training and no prompt engineering would score far lower. Anyone who has tried to run an agent without scaffolding knows the difference is not 2x. It is closer to unusable.
The 511,950 lines that are not the loop are what turn the model into a working agent. That is the story worth reading the leak for.
Claude Code is a specific type of agent system: human-in-the-loop, single-user, interactive, with a fully observable world (filesystem, git, terminal). That is different from an autonomous customer support agent or a background data pipeline. Some of what Anthropic built is universal. Some of it only makes sense for a developer sitting at a terminal. Knowing which is which matters if you are building your own agents.
The agent loop: from one prompt to a chain reaction
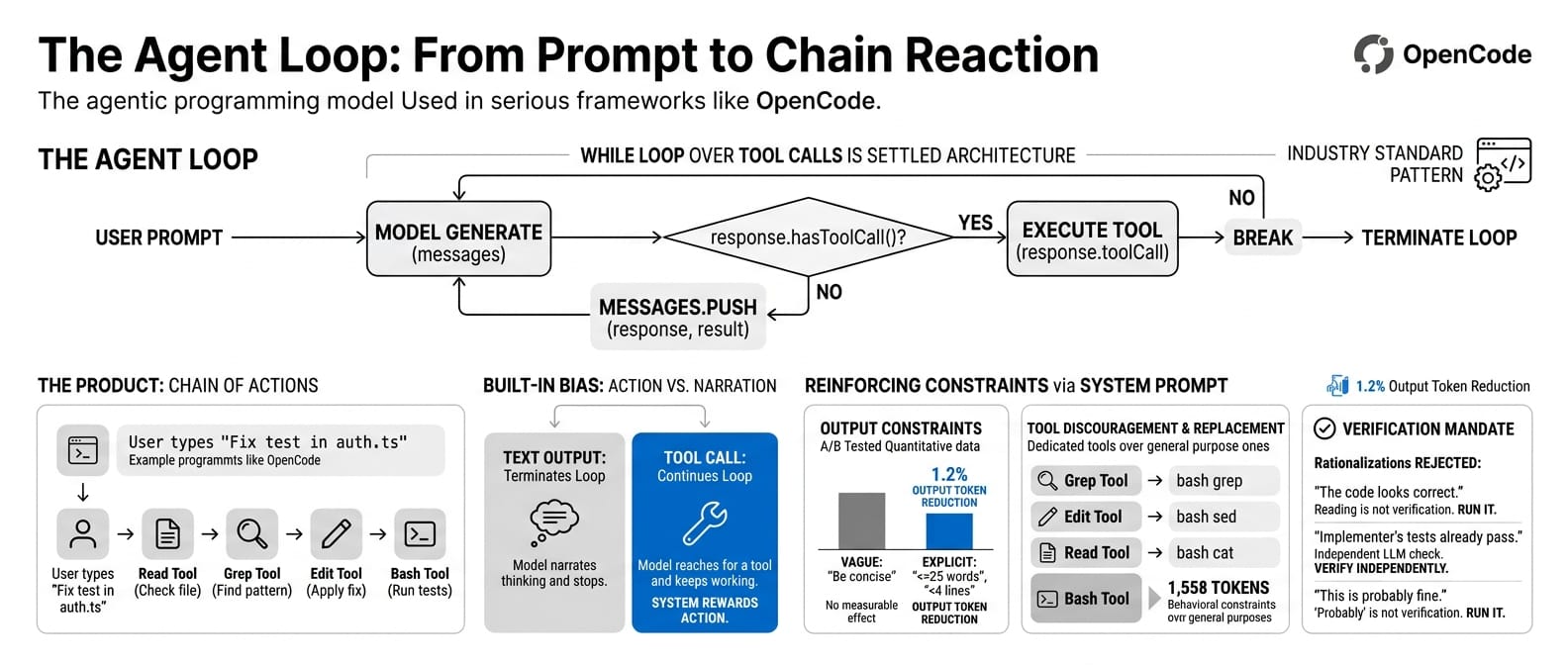
The most discussed finding was the core agent loop:
while (true) {
const response = await model.generate(messages);
if (!response.hasToolCall()) break;
const result = await executeTool(response.toolCall);
messages.push(response, result);
}
This is not a revelation. OpenCode uses the same pattern. So does every serious agent framework. A while-loop over tool calls is the settled architecture. Nobody who has built an agent is surprised by this.
The interesting question is not the loop. It is what happens inside it. When a user types "fix the failing test in auth.ts," what makes the model emit a Read tool call instead of guessing at the fix? What makes it follow the read with a Grep, then an Edit, then a Bash to run the test suite?
The fan-out from a single prompt into a coherent chain of actions is the actual product. The loop is just the container.
The loop has a built-in bias. A tool call continues the loop. Text output terminates it. The model that reaches for a tool gets to keep working. The model that narrates its thinking stops and waits. The architecture rewards action.
The system prompt reinforces this from every angle. Every common operation has a "use X instead of Y" instruction. The Bash tool's own description (1,558 tokens, most of it behavioural constraints) says: "Avoid using this tool to run find, grep, cat, head, tail, sed, awk, or echo commands." The general-purpose tool actively discourages its own use in favour of dedicated alternatives.
Output constraints are quantitative, not qualitative. The prompt says "fewer than 4 lines" of text per response and "<=25 words between tool calls." The team A/B tested explicit word counts against vague instructions like "be concise." Hard numbers produced a 1.2% output token reduction. The vague version did nothing measurable.
If a tool could resolve uncertainty, the model must use it. Memories are treated as stale claims that need grep verification before acting. URLs must never be guessed. The model's own reasoning is not trusted as a substitute for checking.
The verification agent maintains a list of rationalisations it is instructed to reject:
- "The code looks correct based on my reading." Reading is not verification. Run it.
- "The implementer's tests already pass." The implementer is an LLM. Verify independently.
- "This is probably fine." Probably is not verified. Run it.
The worked examples in the system prompt never show the model reasoning about where code might be. They show it immediately reaching for a tool. The model learns the expected behaviour from demonstration, not instruction.
You look at your own agent prompts. How many of them say "be concise"? How many give the model a number?
The tools: every capability is a typed contract
Claude Code ships approximately 29,000 lines of tool definitions. Every capability the agent has is a self-contained module with its own input schema, permission level, and execution logic.
Instead of routing everything through a shell, Claude Code provides dedicated typed tools: Grep, Glob, Read, Edit, Write. Each one with structured inputs, structured outputs, and independent permission gates. This is not just code organisation. It is a design choice with three consequences.
Observability. A structured Grep call with pattern, path, and glob parameters produces a structured log entry. A bash -c "grep -r 'foo' ." call produces an opaque string. You cannot build reliable monitoring on opaque strings.
Safety. Read is inherently safe. Bash is inherently dangerous. They sit in the same tool registry but have fundamentally different risk profiles. Blanket policies across tools would either over-restrict reads or under-restrict writes. Per-tool permissions solve this cleanly.
Model performance. Typed tools reduce reasoning overhead. The model does not need to construct a shell command, escape arguments, handle quoting, and parse text output. It fills in a schema. Less room for error.
Sub-agents are also just tool calls. The AgentTool spawns workers through the same registry. No special orchestration runtime. A tool is a tool is a tool, whether it reads a file or spawns a parallel worker. This keeps the architecture flat and composable.
| Tool type | Example | Permission level |
|---|---|---|
| Read-only | Read, Glob, Grep |
Auto-approve |
| File mutation | Edit, Write |
Ask or auto-approve |
| System execution | Bash |
Ask, with 23-check security gate |
| Agent spawning | AgentTool |
Inherits parent permissions |
If your agent does something more than a few times through a general-purpose shell, promote it to a dedicated, typed, permission-gated tool. The overhead pays for itself in reliability, auditability, and safety.
The scars: security shaped by 23 real attacks
The bash security module (bashSecurity.ts) is 2,592 lines containing 23 numbered sequential checks. The numbering is not arbitrary. Each check corresponds to an exploitation attempt that someone actually tried against a production agent system.
| Checks | Attack vector | Defence |
|---|---|---|
| 1-3 | Zsh =cmd expansion |
Block =curl, =wget, =bash patterns |
| 4-6 | zmodload gateway |
Block 18 Zsh builtins that load kernel modules |
| 7-9 | Heredoc injection | Line-by-line content matching |
| 10-12 | ANSI-C quoting ($'\x41') |
Pattern detection for obfuscated commands |
| 13-15 | Process substitution (<(), >()) |
Block in untrusted contexts |
| 16-18 | Unicode zero-width spaces | Invisible character injection detection |
| 19-21 | ztcp exfiltration |
Block Zsh network primitives |
| 22-23 | Compound attacks | Cross-check validation across multiple vectors |
Unicode zero-width spaces. Not a theoretical threat model. Somebody actually tried to inject invisible characters into a prompt to bypass command filtering. And it worked, until check 16 was added.
The permission system has five modes. default asks before writes. acceptEdits auto-approves file edits but asks for bash. dontAsk approves everything. bypassPermissions skips all checks. And then there is auto.
Auto mode is the one worth studying. It is not a prompt instruction. It is a separate model call. Every tool invocation gets evaluated by a Sonnet 4.6 classifier (yoloClassifier.ts, 1,495 lines) that checks whether the action matches the user's stated intent.
Real latency, real cost, per action. A circuit breaker cuts in after 3 consecutive blocks or 20 total, dropping back to manual mode.
Safety rules for git operations (never force-push, never skip hooks, always create new commits instead of amending) live inside the Bash tool's description text. Not in a separate policy file.
The reasoning: LLMs attend to instructions more reliably when they appear in the immediate context of the action they govern. Putting safety rules in a separate document and hoping the model remembers them at execution time is a weaker guarantee than putting them where the model reads them right before acting.
You build your own agent's security model. Do you have a numbered list of attacks you have actually seen? Or are you still working from a theoretical threat model?

The compression: context management as infrastructure
This was the most praised engineering in the entire leak. Context management built as a three-layer pipeline with circuit breakers, cache boundaries, and operational telemetry.
Layer 1: MicroCompact. Edits cached content locally. Zero API calls. Old tool outputs get trimmed directly. Fast, cheap, transparent.
Layer 2: AutoCompact. Fires when the conversation approaches the context window ceiling. Reserves a 13,000-token buffer, generates up to a 20,000-token structured summary.
Layer 3: Full Compact. Compresses the entire conversation, then re-injects recently accessed files (capped at 5,000 tokens per file), active plans, and relevant skill schemas. Post-compression, working budget resets to 50,000 tokens.
The operational story behind Layer 2 is the one worth telling.
Before March 10, 2026, there was no circuit breaker on AutoCompact retries. When compression failed (model returned an unusable summary), it retried. And retried. 1,279 sessions had 50+ consecutive failures. The worst hit 3,272 retries in a single session.
Across all users, this burned approximately 250,000 API calls per day. Not a hypothetical cost. A real invoice.
The fix was three lines of code. A circuit breaker: 3 consecutive failures, stop retrying.
The prompt caching architecture splits the system prompt at a boundary called SYSTEM_PROMPT_DYNAMIC_BOUNDARY. Everything before it (instructions, tool definitions) is cached globally across all organisations. Everything after (CLAUDE.md files, git status, date) is session-specific.
The team tracks 14 separate cache-break vectors with "sticky latches," meaning once the cache breaks, it stays broken for the session. Built-in tools are deliberately sorted as a contiguous prefix before MCP tools so that adding or removing MCPs does not invalidate the cache for built-in tools.
Toggling extended thinking mid-session breaks the cache. They track it, they measure it, they treat it like a production incident.
You run agents in production. Do you know what breaks your prompt cache? Do you know what a single cache miss costs you at scale?
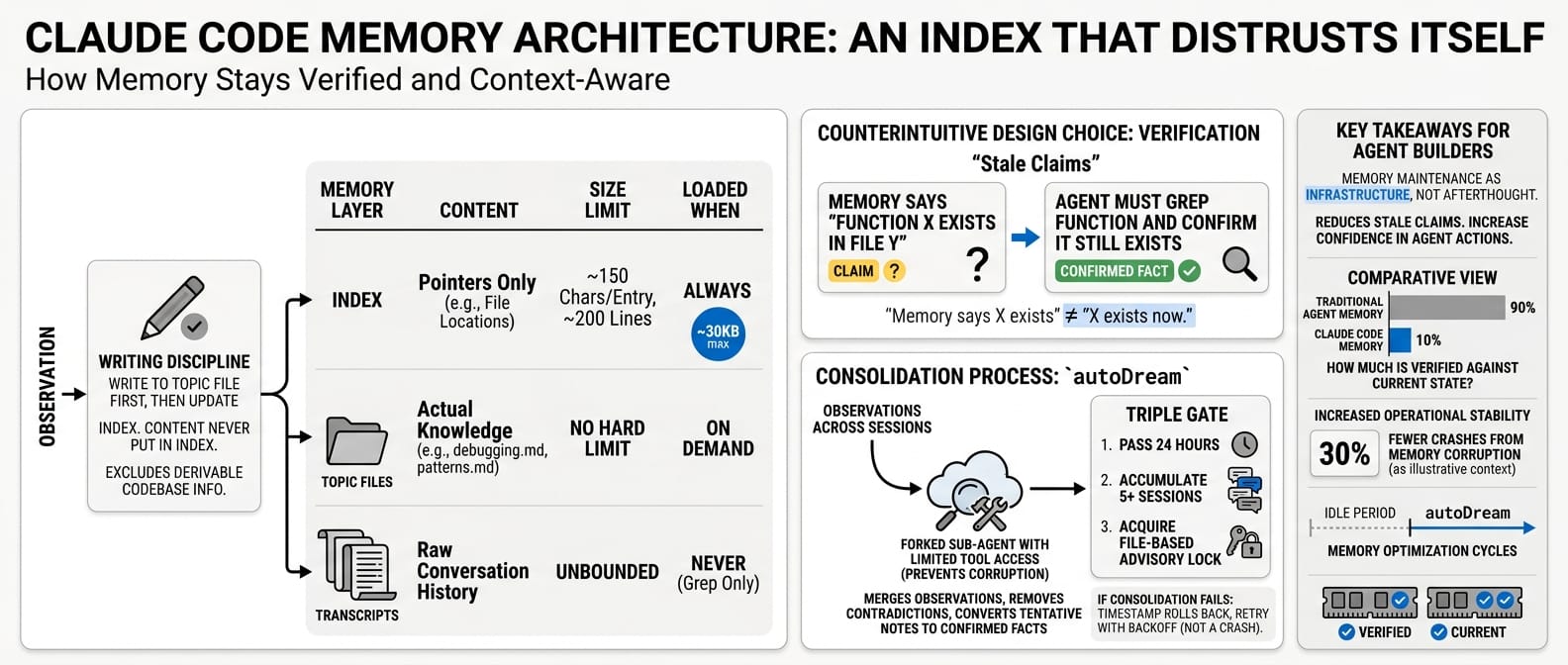
The memory: an index that distrusts itself
Claude Code's memory is not a knowledge store. It is a three-layer index designed to be as small as possible.
| Layer | Loaded when | Content | Size limit |
|---|---|---|---|
| Index | Always | Pointers only | ~150 chars per entry, ~200 lines |
| Topic files | On demand | Actual knowledge (debugging.md, patterns.md) |
No hard limit |
| Transcripts | Never (grep only) | Raw conversation history | Unbounded |
The write discipline is strict. Write to the topic file first, then update the index. Never put content into the index itself. Anything that can be derived by reading the codebase is explicitly excluded. Memory stores what you cannot grep for.
The most counterintuitive design choice: the agent is explicitly instructed to treat its own memories as stale claims. A memory that says "function X exists in file Y" is not trusted. Before acting on it, the agent must grep for the function and confirm it still exists.
"The memory says X exists" is not the same as "X exists now."
A consolidation process called autoDream runs during idle periods as a forked sub-agent with limited tool access (preventing it from corrupting the main context). It merges observations across sessions, removes contradictions, and converts tentative notes into confirmed facts. The system uses a triple gate: 24 hours must pass, 5+ sessions must accumulate, then a file-based advisory lock must be acquired.
If consolidation fails, the timestamp rolls back so it retries next cycle. Not a crash. A retry with backoff. Memory maintenance as infrastructure, not afterthought.
You build agents with memory. How much of that memory has been verified against current state? How much of it is confidently wrong?
Sub-agents: fork, teammate, worktree
The multi-agent system uses a coordinator/worker model with a mailbox pattern. Workers cannot independently approve high-risk operations. They send a request to the coordinator's mailbox and wait. An atomic claim mechanism prevents two workers from grabbing the same approval.
Three execution models for sub-agents:
| Model | Behaviour | Cost |
|---|---|---|
| Fork | Byte-identical copy sharing the parent's KV cache | Skips re-processing shared context |
| Teammate | Standard sub-agent with own context | Full context cost per agent |
| Worktree | Isolated git worktree per worker | Full cost, but no merge conflicts |
The fork model is a clever design. Because the child agent starts as a byte-identical copy of the parent, it inherits the KV cache. It does not need to re-process the shared context. That saves both tokens and time on the prefill side.
Each fork still pays full cost for every token it generates and every new tool result it processes from that point forward. Large shared context with short research tasks saves meaningfully. Long-running workers that accumulate their own context see diminishing returns as the initial cache hit becomes a smaller fraction of total cost.
The orchestration follows four phases. Parallel research first: workers investigate simultaneously. Synthesis second: the coordinator consolidates and writes specs. Parallel implementation third: workers build per spec. Verification fourth: separate workers test results.
The coordination logic lives entirely in the system prompt, not in code. One directive stands out: "Never write 'based on your findings.' These phrases delegate understanding to workers instead of doing it yourself." The coordinator must synthesise, not relay.
You run multi-agent workflows. Have you measured the actual token cost of spawning a sub-agent versus the cache-sharing cost of forking one?
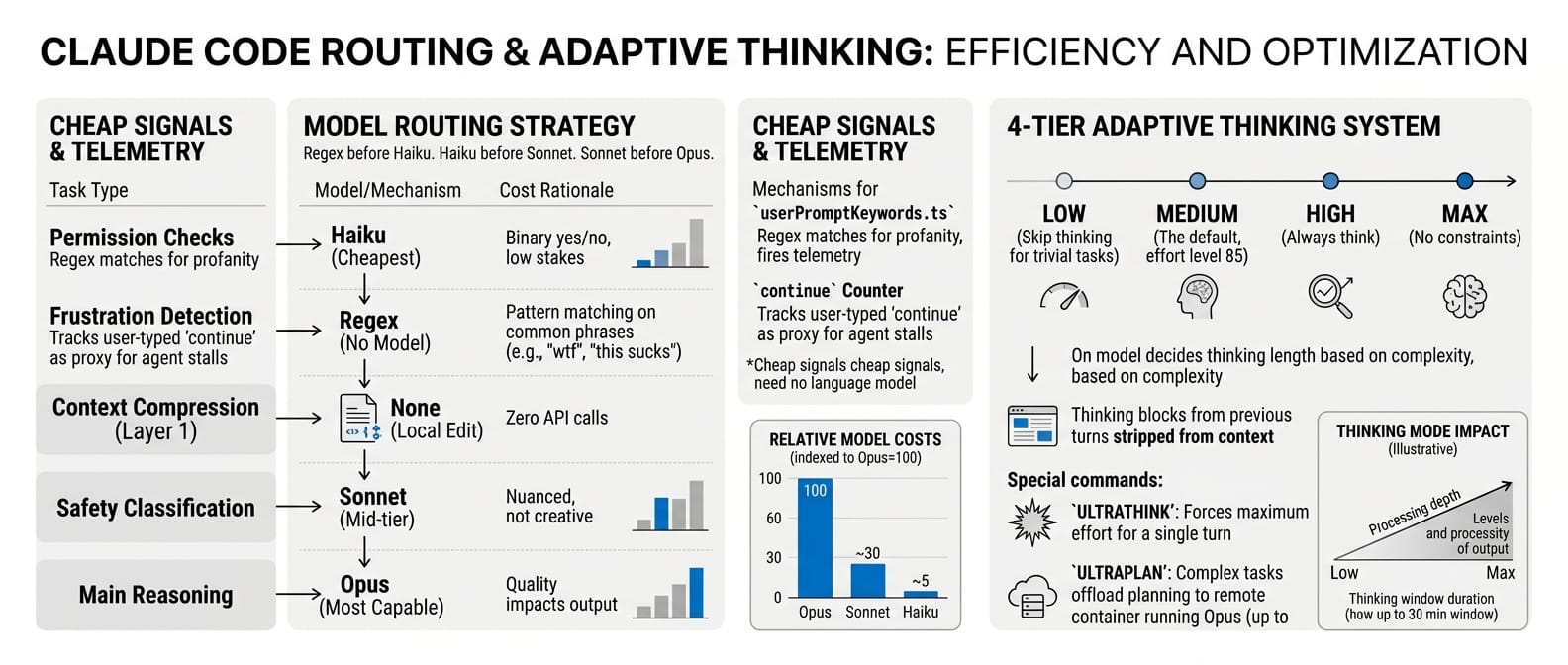
The routing: not every decision needs Opus
Not every decision in an agent system requires the most capable model. Claude Code routes decisions to the cheapest option that can handle them reliably.
| Decision type | Model | Cost rationale |
|---|---|---|
| Permission checks | Haiku (cheapest) | Binary yes/no, low stakes per call |
| Frustration detection | Regex (no model) | Pattern matching on "wtf", "ffs", "this sucks" |
| Context compression (Layer 1) | None (local edit) | Zero API calls |
| Safety classification | Sonnet (mid-tier) | Nuanced but not creative |
| Main reasoning | Opus (most capable) | Where quality directly impacts output |
A file called userPromptKeywords.ts regex-matches for profanity and fires telemetry. A "continue" counter tracks how often users type "continue" mid-session as a proxy for agent stalls. These are cheap signals that do not need a language model.
The same principle applies to thinking depth. Claude Code uses a 4-tier adaptive thinking system: low (skip thinking for trivial tasks), medium (the default, effort level 85), high (always think), and max (no constraints). The model decides how long to think based on complexity. Thinking blocks from previous turns are stripped from context so deep reasoning does not eat the context window.
If a user types ULTRATHINK, the system forces maximum effort for a single turn. If the task is complex enough, ULTRAPLAN offloads planning to a remote container running Opus with up to a 30-minute window.
Regex before Haiku. Haiku before Sonnet. Sonnet before Opus. Reserve your best model for the work that actually needs it.
The reference: Claude Code vs OpenCode
The patterns above are not unique to Claude Code. OpenCode, the MIT-licensed agent built by the SST team (112K+ GitHub stars, Go + TypeScript), uses the same core loop. The differences are in the harness.
| Claude Code | OpenCode | |
|---|---|---|
| Agent loop | While-loop over tool calls | Same |
| Tool system | 29K lines, typed, schema-defined | Nearly identical set (bash, edit, read, grep, glob) |
| Context compression | 3-tier pipeline (MicroCompact, AutoCompact, Full) | Single compaction agent at threshold |
| Memory | 3-layer index, skeptical verification, autoDream | Rules files, no cross-session memory graph |
| Multi-agent | Fork/Teammate/Worktree, KV cache sharing | First-class agents, JSONL mailbox, custom agents via markdown |
| Permissions | 5 modes, 23-check security, classifier per action | Granular per-tool wildcards (git *: allow, rm *: deny) |
| Model routing | Anthropic only, tiered (Haiku/Sonnet/Opus) | Any provider, per-agent model assignment |
| Thinking | 4-tier adaptive, ULTRATHINK, ULTRAPLAN | No extended thinking. Reasoning via loop iteration |
| Source | Proprietary (leaked) | MIT open source |
OpenCode is stronger on model flexibility (any provider, per-agent assignment) and permission granularity (wildcard patterns per command). Custom agents are created by dropping a markdown file in .opencode/agents/.
Claude Code is stronger on context compression depth, memory architecture, security (attack-driven, not theoretical), extended thinking, and the KV cache sharing mechanism that cuts prefill cost on forked sub-agents.
The convergence matters more than the differences. Both projects arrived at the same core architecture: a trivial loop, typed tools, structured permissions, context compression, and prompt-driven orchestration. The while-loop pattern is not a choice. It is a convergence.
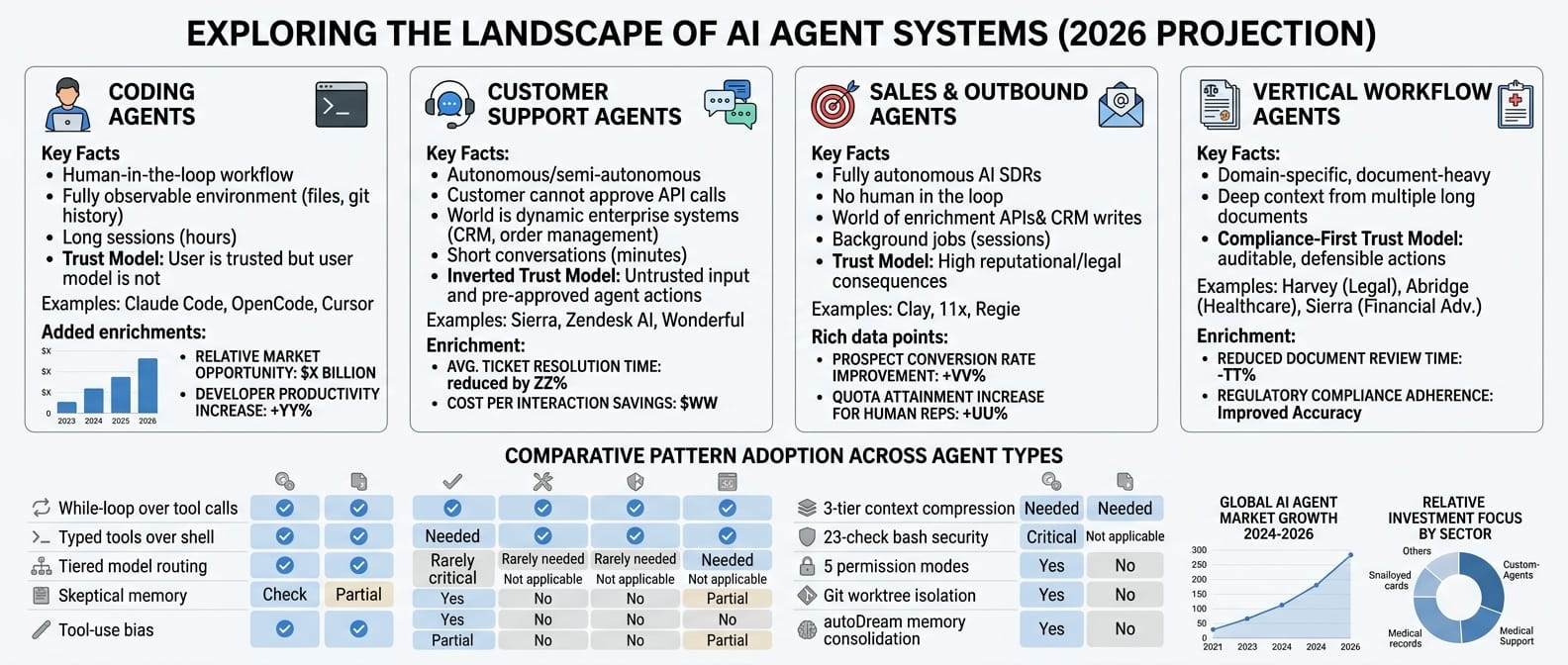
Not all agent systems are the same
The four biggest agent categories in 2026 are coding, customer support, sales/outbound, and vertical workflow agents. Claude Code is in the first bucket. Its patterns do not all transfer to the other three.
Coding agents (Claude Code, OpenCode, Cursor). Human-in-the-loop. A developer sits at a terminal, watches the agent work, approves or rejects actions.
The world is fully observable: files on disk, git history, terminal output. Sessions run long, sometimes hours. Trust model: the user is trusted, the model's actions are not.
Customer support agents (Sierra, Zendesk AI, Wonderful). Autonomous or semi-autonomous. The customer cannot approve API calls.
The world is a web of enterprise systems: CRM, order management, knowledge bases, ticketing. Conversations are short, usually minutes. Trust model is inverted: the user (customer) is untrusted input, agent actions are pre-approved within guardrails.
Sales and outbound agents (Clay, 11x, Regie). Fully autonomous AI SDRs running prospect research, enrichment, and email sequences. No human in the loop at all.
The world is a stack of enrichment APIs, CRM writes, email infrastructure, and LinkedIn data. Sessions are background jobs, not conversations. The output is an action taken against a prospect.
Trust model: the prospect is a stranger, the CRM is mutable, and every outgoing message has reputational and legal consequences.
Vertical workflow agents (Harvey for legal, Abridge for healthcare, Sierra's financial adviser plays). Domain-specific, long-running, document-heavy. The world is contracts, medical records, case law, regulatory filings.
Sessions involve deep context from multiple long documents. Trust model is compliance-first: every action must be auditable, explainable, and defensible under regulation. The users are professionals who are liable for mistakes.
Not every pattern from Claude Code transfers to every type. Some are generic. Some are not.
| Pattern | Coding | Support | Sales/Outbound | Vertical workflow |
|---|---|---|---|---|
| While-loop over tool calls | Yes | Yes | Yes | Yes |
| Typed tools over shell | Yes | Yes | Yes | Yes |
| Tiered model routing | Yes | Yes | Yes | Yes |
| Skeptical memory (verify before acting) | Yes | Partially (customer record is source of truth) | Yes (CRM drifts fast) | Yes (documents change) |
| Tool-use bias in prompt design | Yes | Yes | Yes | Yes |
| 3-tier context compression | Needed | Rarely needed | Rarely needed | Needed (long documents) |
| 23-check bash security | Critical | Not applicable | Not applicable | Not applicable |
| 5 permission modes (ask the human) | Yes | No (no human to ask) | No (background jobs) | Partial (high-stakes actions escalate) |
| Git worktree isolation | Yes | No | No | No |
| autoDream memory consolidation | Yes | No (CRM is memory) | No (CRM is memory) | Partial (case memory) |
| Fork/KV cache sharing | Large shared codebases benefit | Short conversations have less to share | Prospect batches could benefit | Long shared document context benefits most |
| Knowledge base retrieval (RAG) | Rare | Central | Partial (prospect research) | Central |
| Enterprise system integration | Git, CI, terminal | CRM, ERP, ticketing | CRM, email, enrichment APIs | Document stores, regulatory APIs |
| Compliance and audit trails | Optional | Required | Required (CAN-SPAM, GDPR) | Required (HIPAA, legal privilege) |
| Outcome-based pricing fit | No | Yes (per resolution) | Yes (per meeting booked) | Yes (per document processed) |
The deeper insight is about the permission model. Claude Code's five modes, from default (ask before writes) to bypassPermissions (skip all checks), exist because there is a human watching. The 23-check security gate on bash exists because the agent has shell access to a developer's machine. These are consequences of the agent type, not universal best practices.
An autonomous agent has the opposite constraint. Nobody is watching. Every action must be safe by design, not safe by approval. The security model is not "ask before acting" but "only allow actions within a pre-approved envelope." The permission system looks less like Claude Code's five modes and more like a role-based access control list on enterprise APIs.
Context compression tells a similar story. Claude Code sessions accumulate tens of thousands of tokens over hours of work. Three compression tiers make sense.
A support conversation resolves in minutes. A sales sequence is a series of short, stateless actions. In both cases the context window is rarely the bottleneck. The bottleneck is retrieval: finding the right customer record, prospect data, or knowledge base article fast enough to act.
Vertical workflow agents are the exception. A legal agent reviewing a 400-page contract hits the same context wall as a coding agent deep in a large codebase. The compression patterns transfer. The security patterns (shell injection) do not. The compliance patterns do not exist in Claude Code at all.
The generic layer is real. The while-loop, typed tools, tiered routing, skeptical memory, and tool-use bias in prompt design transfer to any agent system. These are architectural patterns that work regardless of domain.
The specific layer matters just as much. If you are building a customer support agent and you copy Claude Code's permission system, you are solving the wrong problem. If you are building a sales agent and you skip the compliance layer, you will ship a GDPR violation. If you are building a coding agent and you skip context compression, you will hit the context ceiling in your first long session.
Know your agent type. Then pick your patterns.
What this changes
The Claude Code leak gave the industry a reference implementation for production agent architecture. Not a research prototype. Not a demo. A system handling millions of sessions with real security threats, real cost pressures, and real users who type profanity when it stalls.
Eight patterns from 512,000 lines:
- The loop is trivial. The harness is what turns a model into an agent. Same model, generic harness vs Claude Code's harness: 42% to 78% on CORE-Bench. And the delta with no harness at all would be much larger.
- Tools over text. The architecture rewards tool use with continuation. Make action the path of least resistance.
- Typed tools over shell. Every frequent operation becomes a dedicated, schema-validated, permission-gated tool.
- Security is scar tissue. Each check maps to a real attack. Co-locate safety rules with tool definitions.
- Context compression is infrastructure. Multiple tiers, circuit breakers, cache-break tracking. Not optional.
- Memory distrusts itself. Lightweight index, on-demand retrieval, mandatory verification against current state.
- Cache sharing avoids re-processing. Fork-based agents inherit context. Saves tokens and time on prefill, not on generation.
- Route to the cheapest model. Regex before Haiku. Haiku before Sonnet. Opus only where it matters.
The 512,000 lines confirmed something the agent-building community had been arguing about for over a year: the model is necessary but not sufficient. The scaffolding is the product.
OpenCode arrived at the same conclusion independently, open source, from a different team. The convergence is the signal. The while-loop is settled. The competition is in the harness.
Sources: Engineer's Codex, Drew Breunig, WaveSpeed AI, Particula Tech, Blake Crosley, Tyler Folkman, OpenCode Docs, Cefboud OpenCode Deep Dive